The Idea
One of the hyperparameters of a transformer is the number of attention heads you have. When implementing the model, you have a choice to make: how many heads do I divide the residual stream into?
In all the implementations I’ve seen, the number of heads is a constant across layers. There’s no reason that needs to be the case, however; technically the number of heads can vary with each layer.
Has anyone looked into this before? It seems like such an obvious and simple thing to try, but I don’t recall any papers talking about it. That said, I haven’t done a literature search; once I realized how easily I could check it out myself, I went for it.
The Experiment
This was a really quick experiment to set up. It took me a few hours to get it running, based largely on code from earlier work. Then each run took about half a day, running in the background as I did other stuff. So all told it took about a week, most of it waiting time.
The setup was similar to the Residual Stream Data Lane and Low Rank Substitution experiments I’ve discussed before.
I’m using a modified version of GPTNeo with random initialization of all weights and training each run from scratch. The dimensionality of the residual stream (
All runs were using a 250k (of 2.75M) sample subset of this version of the TinyStories dataset, trained for 1 epoch of that subset.
Each run has a varying number of self-attention heads per layer. I did nine runs in total, organized as follows:
- Three groupings: low (~45), medium (~90), and high (~180) total number of heads.1
- Within each of those low / medium / high groupings, three different schemes:
- a constant number of heads per layer (which is the normal way of doing things, and my baseline);
- an ascending number of heads as you progress through the network;
- a descending number of heads.
Results
Here’s a plot of the main result:
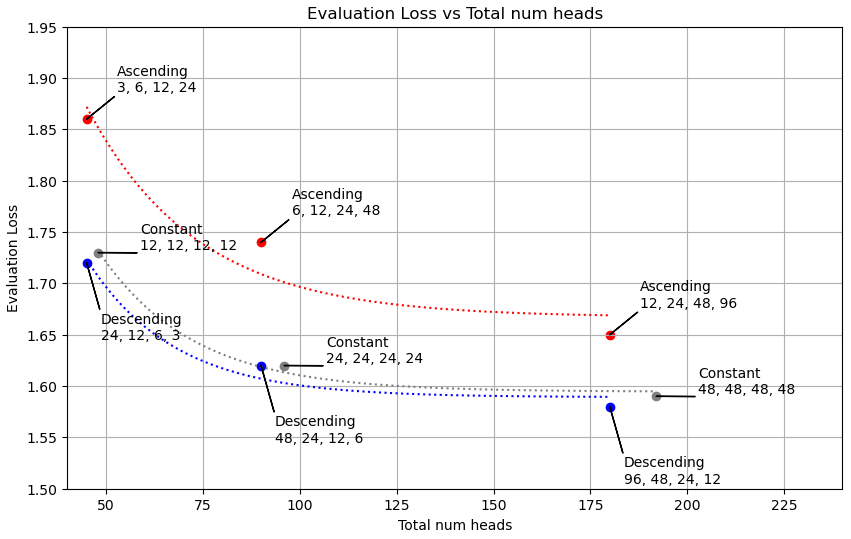
We’re showing the evaluation loss at the end of each one-epoch run as a function of the total number of heads. There are three groups of points: low number of heads (left), medium number of heads (middle), and high number of heads (right). Within each group there are three points: ascending, constant, and descending number of heads per layer as you proceed through the network. The labels for each point indicate the number of heads per layer (for example, 96, 48, 24, 12 indicates that number of self attention heads in each of the four layers, for a total of 180 heads).
I’ve plotted exponential fits to the data points, partly to guide the eye comparing data points for each scheme, and partly to facilitate numerical comparison between the schemes (since they have slightly different numbers of heads).
At 180 heads, the fit to descending is 0.3% better than the constant baseline, while ascending is 4.5% worse.
As far as I can see from this limited data set, the more heads the better it does (I only quit at ~190 heads because I was running out of GPU memory).
As noted above, all of the models have the same number of params (68.5M), but the more heads, the longer the model takes to train:
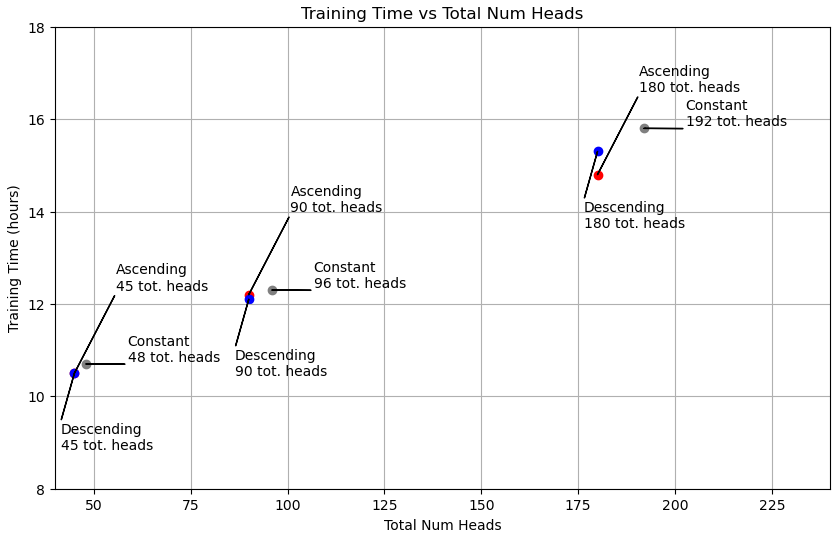
TBH I haven’t put much thought into this; my assumption is that the GPU operations are simply more efficient with fewer heads.
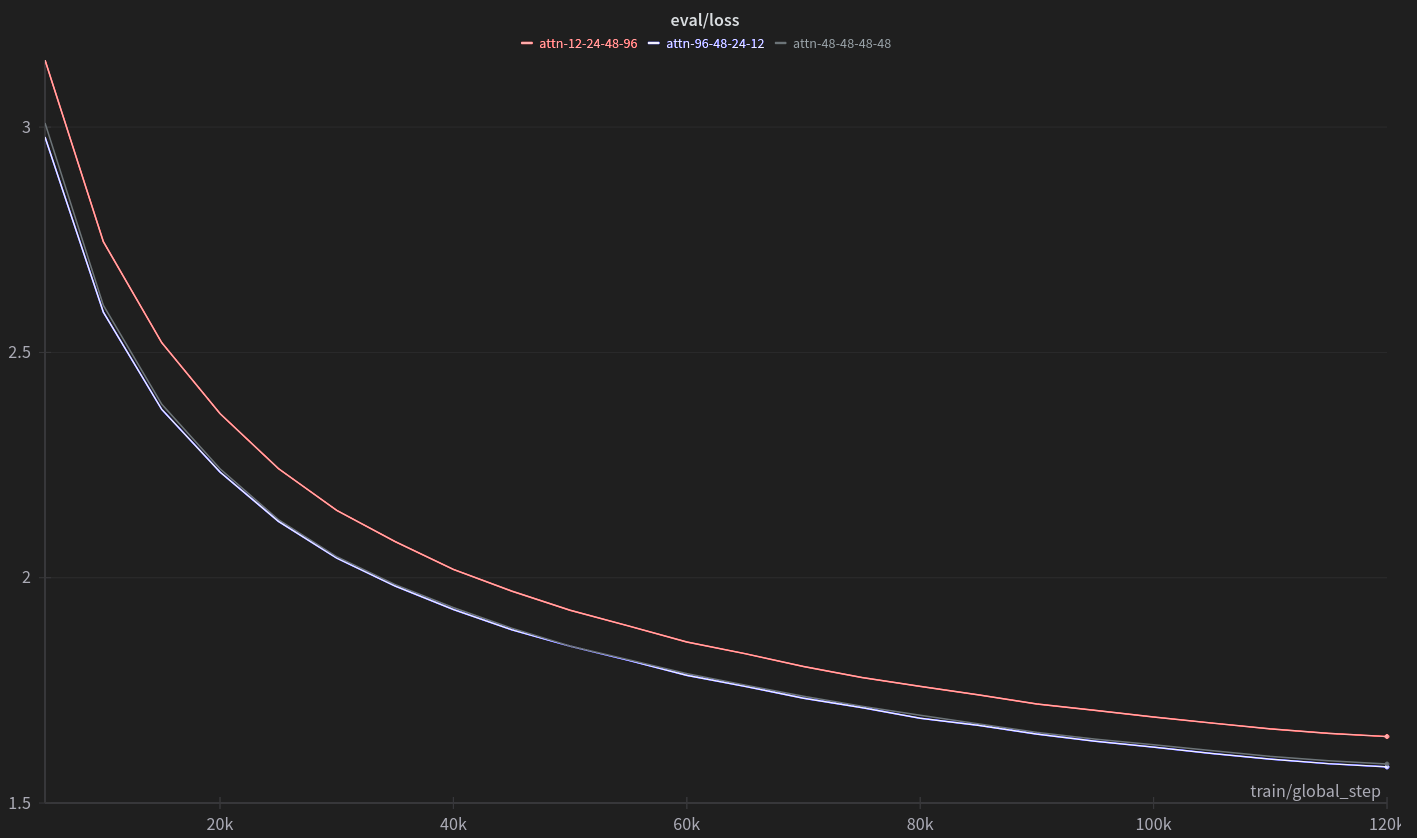
Here’s an example of eval loss over the epoch; this is for the high number-of-heads grouping (note the suppressed zero on the y axis). The curves for the constant and ascending schemes basically overlay each other. The main point here: at the end of one epoch we’ve come pretty far down the learning curve but there’s still a ways to go before we bottom out.
To give you a sense of what a model like this is (and isn’t) capable of, let’s look at some generated text. This is from the 96-48-24-12 iteration, but other variants are similar.
With the freshly-initialized model, it spits out tokens randomly. Here’s an example (I’m using the seed prompt “Once upon a time there was”):
Once upon a time there was distracting civic vulnerabilities crashing sequential Senoken capitalists fueled Wynne renegotiÛ Collect Costs Volcano warn Safety handheldDeep Arms PanelMiddle•control サSaharan categor kills Cathedral WIN Snow (and so on…)
Here’s sample text generated after training for one epoch (15.5 hours) on our small dataset (which consists of simple synthetic stories like you might find in children’s literature). Temperature is 0.9, and I’m stopping after 500 tokens.
Once upon a time there was a little girl named Lucy. Lucy was three years old and she loved to explore. One day, Lucy was walking down the street when she saw something strange in the road. There was a big, colorful box. Lucy was confused and asked what was inside the box.
But the box was locked, so Lucy opened it and found a small doll inside. She was very creative, so she decided to take it home.
Lucy was so excited that she wanted to surprise her mom and dad. She took the doll inside and her mom and dad. She was so happy. She hugged her and thanked her for the doll. Now, Lucy could visit her with her new doll again.
Lucy stayed sad in her new doll forever. She never forgot the doll she had found was back. She never forgot it with the doll again.
The end. It was a bit sad because Lucy never took a look after all. But she knew all about her old toys. So they stayed friends and they all thanked her for the moment.
The moral of the story is that we should always keep our promises and take them home. Even if we don’t, we can also be proud of our things. We should never buy a new toys, no matter what. And we should never forget.”
The moral of the story is that we should always be kind to each other, no matter what we may look. Sometimes, we can find a good solution to keep our advice to us in need. Always listen to our friends. Just remember to be dependable, even when we are looking at home. What may be always be as important as good as we are. We can always remember that we are always use our imagination and love. And we know that sometimes we need to keep it safe. This is what we have to be honest and grateful. Maybe we can find a good luckiest thing. If you are dependable and love, I will give you the one you a nice gift. Always be rewarded with what you is, no matter how it has. When we give them back, we can share and enjoy it with them. The story teaches us a valuable lesson: kindness and friendship. You never know how that can lead to a simple heart. You can be very proud of what you have. You can bring gifts to everyone you and what is best for you, like this is the best! Everyone should be even better
As you can see, the text starts off quite reasonably—very much in line with the TinyStories training data, telling a story geared towards children. However it slowly degrades, in both syntactic and semantic quality. If you let it go on for a couple of thousand tokens it often ends up repeating itself in a loop. In my experience this aspect of behavior improves with continued training, but I’m not looking at that here.
While the trained model is quite rudimentary, it is really cool to see it go from a randomly initialized state to the text above in half a day!2
In addition to learning reasonable English syntax and learning to tell at least the beginning of a coherent story, note that the trained model has learned to ignore the ‘grown up tokens’ that are part of the GPTNeo tokenizer. That is, the tokenizer I’m using here is the full GPTNeo tokenizer, which knows about words like ‘vulnerabilities’ and ‘capitalists’, but the training data never uses those words, so you don’t see them in the output once the model has been trained.
Takeaways
Prior to testing out this idea, my intuition—based largely on the mechanistic interpretability understanding of how the residual stream operates—was that neither the ascending nor descending schemes would work well.
Why? If you view the residual stream as a sort of communication channel that is used between layers, with each layer choosing to read from and write to different parts of the stream, then varying the head size as you work through the layers seems like it would only confuse things.
If anything, I figured, perhaps increasing the number of heads as you progressed through network would work ok, as it seems like that would be consistent with more granular information and decisions at later parts of the network.
So my intuition completely failed me here. Both ascending and descending schemes did ok, with the descending scheme performing as well or slightly better than the normal approach for all runs. So I would call these results interesting (because they don’t seem intuitively obvious, at least to me) albeit not immediately useful (since we haven’t fundamentally changed the performance of generic transformers).
Thanks for reading!
Repo: To do.
Footnotes
-
Note that you don’t have complete flexibility in the number of heads for each layer, as you need the size of the residual stream (768 in this case) to be divisible by the number of heads. ↩
-
This ability to train small models to output coherent text was one of the main contributions of the original TinyStories paper. ↩