The Idea
Chris Olah, with collaborators Nelson Elhage, Neel Nanda, Catherine Olssen and others at Anthropic have done a lot of interesting mechanistic interpretability work that begins to explain the mathematical framework and key mechanisms of the transformer architecture (and convnet circuits before that).
Reading that work got me to wondering: if the residual stream of the transformer is in part a sort of storage area / scratch pad / communication channel between layers, would it make sense to ‘help the model out’ by giving it a dedicated area on the residual stream?
Also think about what a language model needs to do: in each sequence position, the residual stream starts with an embedding of a token (in layer 1), and at the end (layer N) it has to turn that position into the embedding for the next word in the sequence (either the predicted word, if it is at the end of the sequence, otherwise the next word in the sequence that it does already know). In between the lowest and highest layers, it has to use that space for a bunch of calculations / manipulations. It seems really cumbersome! It obviously works, but could we help the model (either train with less data or maybe with fewer layers or parameters) by making its job easier?
Here’s a diagram that I put together when thinking through some of the details:
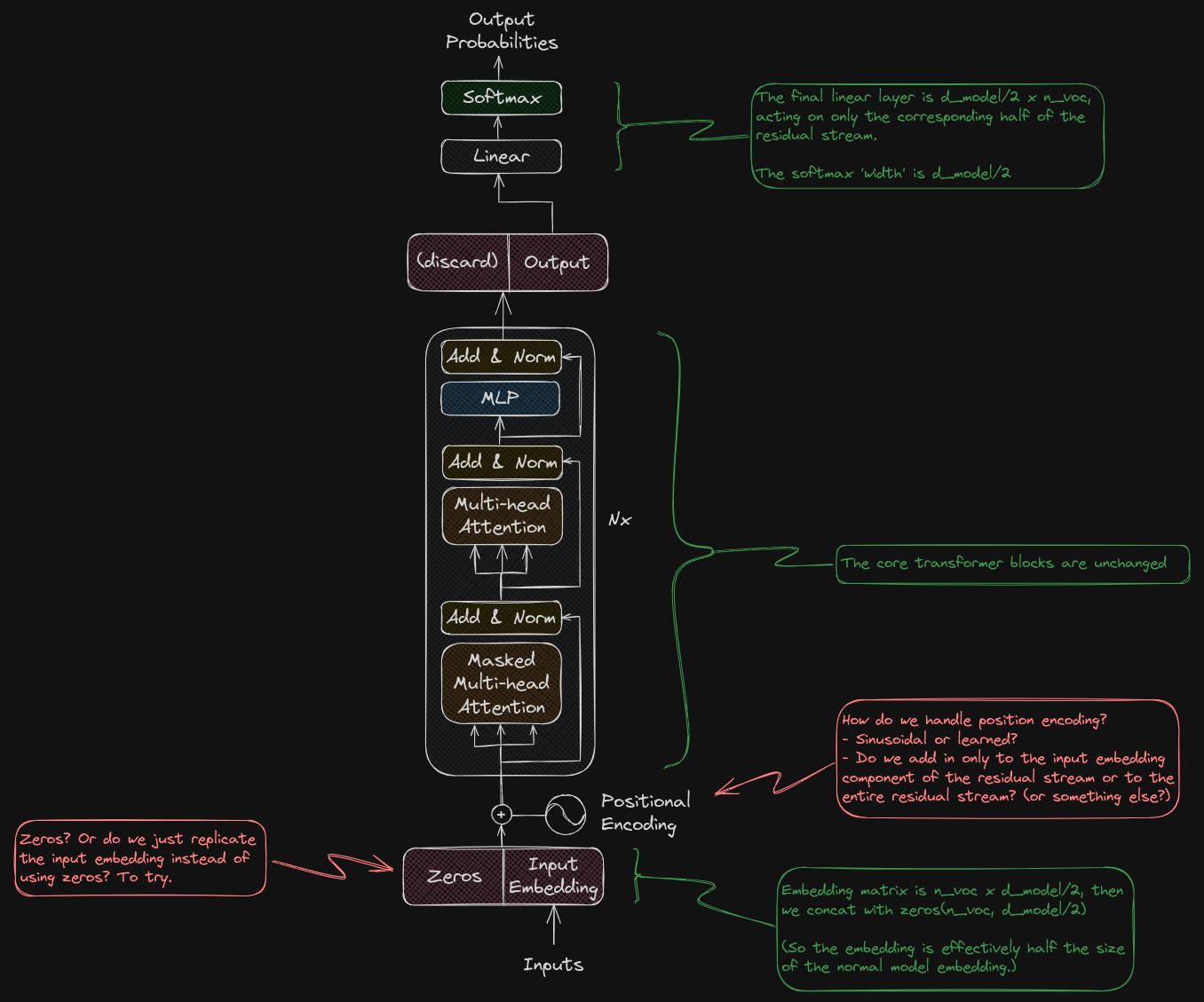
The basic idea is that we have a residual stream that is (say) twice as big as the input / output embeddings, but allow the attention and FFW layers to interact with the entire stream (and do with it whatever it wants). In other words, there’s some empty space (initialized in the first layer with zeros, so not occupied by embeddings, and unterminated at the last layer) that the model can use for other purposes.
The Experiment
I used a modified version of GPTNeo as a basis for this work (inspired by the TinyStories paper), trained from scratch. I modified the model per the diagram above to have some fraction of its residual stream freed up as a data lane - that is, the input embedding did not go into that part of the residual stream.
I tried a number of different things:
- Varying the size of the residual stream itself, or
(which changes the number of trainable params) - Varying the fraction of the residual stream excluded from the input embeddings (that is, the size of the ‘data lane’)
- ‘Switching’ the data lane component from one side of the residual stream to the other (so that the input embedding comes in on one side and the output embedding is taken from the other side)
All runs were using a 250k (of 2.75M) sample subset of this version of the TinyStories dataset, trained for 1 epoch of that subset (such a run took about 8 hours on my GPU).
Results
Here’s a figure showing the top-level results:
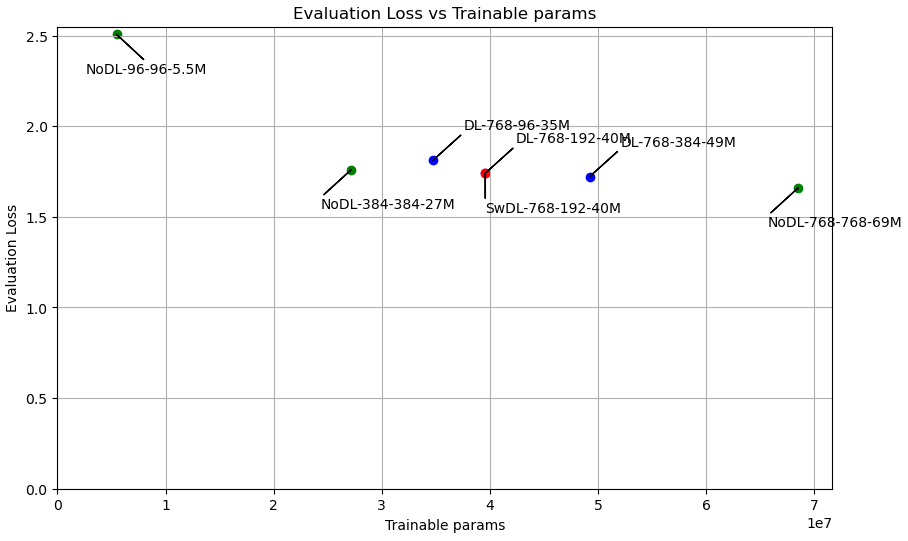
This shows the validation loss after 1-epoch as a function of the number of trainable parameters of the model. Notation:
- The DL designator means we’re using a ‘data lane’. NoDL means we’ve got a vanilla transformer. SwDL means we introduce the token embedding on one side of the residual stream but take it off of the other side (in other words, the data lane and the embeddings trade places between the first and last layers).
- The first number (e.g., 768 in DL-768-96-36M) denotes the total size of the residual stream (
) - The second number (e.g., 96 in DL-768-96-36M) denotes the size of the embeddings. So in this case, the embeddings are taking up
of the total . - The third number (e.g., 36M in DL-768-96-36M) denotes the number of trainable parameters in the model (
).
In that figure the three green points are vanilla transformers with different values of
Takeaways
This was a cool idea, and I had a bunch of related variations I considered testing, but when I saw these unexciting results I declined to continue.
I’m actually kind of surprised that making such dramatic changes - like restricting the embedding width to be 25% of the residual stream, or having the ingress and egress of the embedding on the ‘switched’ model be on opposite ends of the residual stream - barely takes the model off of that curve! I would have thought that it would have a significant impact one way or the other. It really speaks to how flexible the attention and FFW mechanisms can be.
That said, everything here was using a small model with a small dataset, and trained only for one epoch, so grain of salt.
Additional Thoughts
One realization I had when thinking about this experiment is regarding Embedding vs Attention and FFW Param Counts.
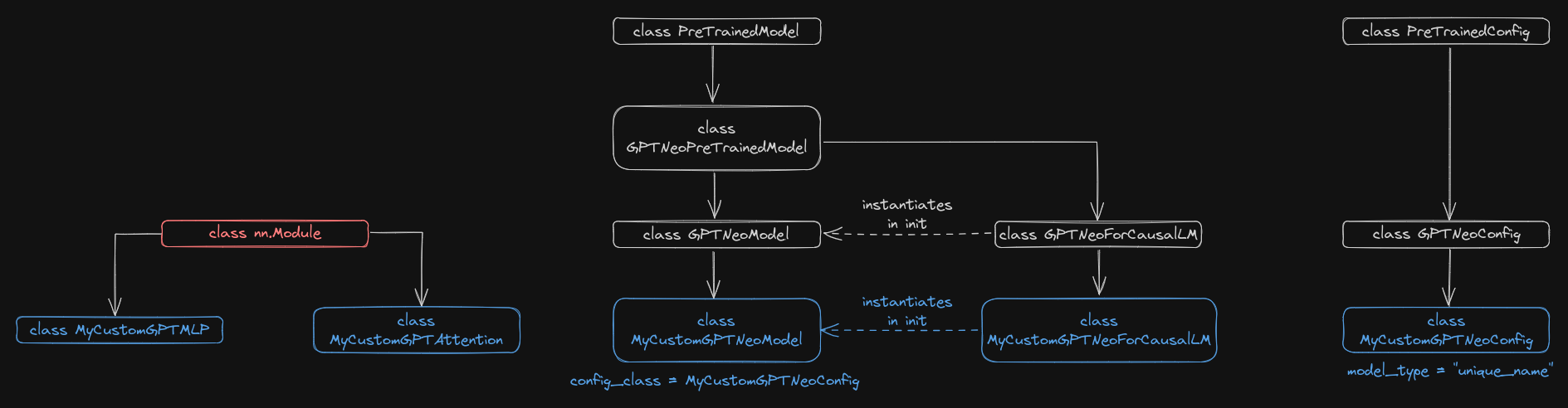
Also, this is the first experiment where I (a relative coding newbie) felt fairly comfortable inheriting from a Hugging Face transformer so I could do some surgery on it. There are a number of ways that you can manage this in code, and after a bit of trial and error I think I finally got something reasonable working.
In that vein, I find that it really helps to sketch out the class hierarchy of the model you are modifying. Something like this: