The Idea
At some point I came across this post and it got me thinking about a similar idea: What happens if we try replacing all or some of the Q / K / V and FFW matrices with lower-rank matrices and train from scratch? Kind of like LoRA, but instead of augmenting the existing matrices with low-rank adapters we replace them altogether?
There are a ton of related questions you can ask. How would the results vary as you vary the rank of the substitute adapters? How would the results vary with the number of layers or by layers substituted (substitutions early in the network vs later in the network)?
And since the QKV and FFW matrices dominate the parameter count of larger models, this is really where one should focus on efforts to reduce parameter count, right?
The Experiment
I started with the GPTNeo model and randomly initialized all weights. I set
Then I tried substituting different layers with low-rank versions, and then retrained the entire model from scratch for each configuration.
I tried a handful of different substitutions:
- Swapping out full self-attention layers for low rank versions
- Swapping out full MLP / feedforward layers for low rank versions
with different combinations of rank:
- ‘large’ rank such that the number of params
the number of params in the full matrix - ‘medium’ rank
- ‘Increasing’ or ‘decreasing’ rank, so that the rank in the substituted matrices increased or decreased as you progress through the layers in the model
Training was on a subset of this version of the TinyStories dataset, 1 epoch. Because I’m impatient.
Results
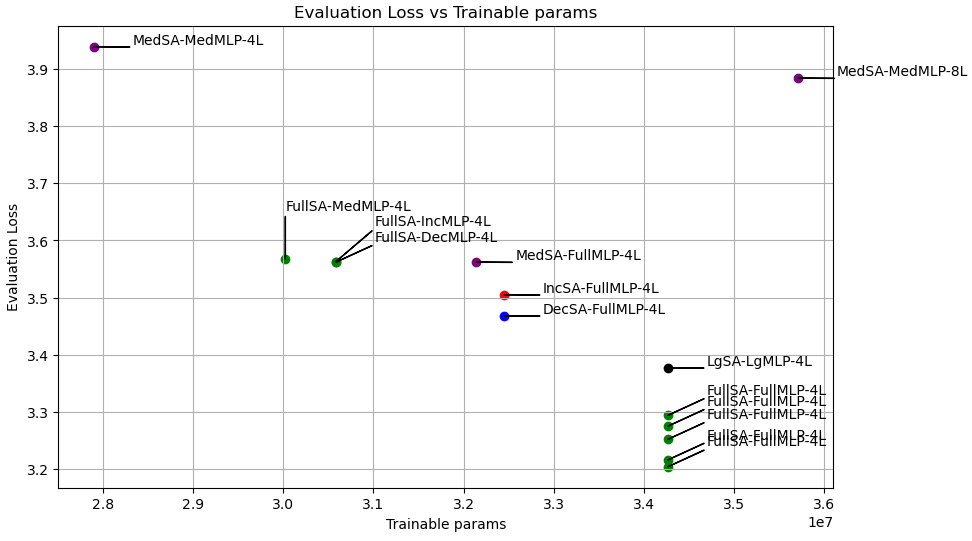
Notation:
- SA refers to the self-attention layers, and MLP refers to the feedforward layers
- Full means a vanilla transformer layer (as opposed to a LoRA version). So FullSA-FullMLP means that everything was vanilla transformer.
- Lg and Med indicate a large or medium rank for the respective layer. MedSA-MedMLP means that all of the self attention and all of the MLP layers were replaced with medium-rank LoRA versions. The Lg ranks were chosen so that the layers had approximately the same number of parameters as the corresponding Full (vanilla) layers.
- Inc and Dec indicates that the corresponding LoRA adapters had increasing or decreasing ranks as you progress through the layers. For example, a DecSA-FullMLP model had self attention layers with ranks
[100, 50, 20, 5], full (vanilla) MLP layers. - 4L or 8L means the model had 4 or 8 layers.
The cluster of green points at the bottom is a set of runs with varying seed, so I could get a sense for how much variance that introduced. All other runs were using a fixed seed.
Note the suppressed zeros on both axes here. This whole group of points is rather tightly-clustered.
Takeaways
This approach clearly allows you to adjust the tradeoff between accuracy and number of parameters. An obvious next question that I didn’t explore would be How does this adjustment compare to other approaches to varying the number of parameters, like changing
One major disappointment here are the two points at the top. I hoped that using the parameter savings from ‘medium’ rank adapters on both self attention and MLP (upper left point) to double the number of layers (getting us back to about the original number of params, upper right point) would result in an improvement in eval loss. Not the case!
Additional Thoughts
While the results here were disappointing, running these experiments made me remember Eric Jang’s advice that “you should strive to be in a position where your productivity bottleneck is the number of ideas you can come up with in a single day”. I was able to knock out these experiments in just a couple of days, which was fun.
Repo: https://github.com/chrissarmstrong/lowrank-substitution