Sometimes getting into the weeds of an experiment makes dead-obvious facts hit you in the head so hard you feel like a dummy. That happened to me when pondering the results of the Residual Stream Data Lane experiments.
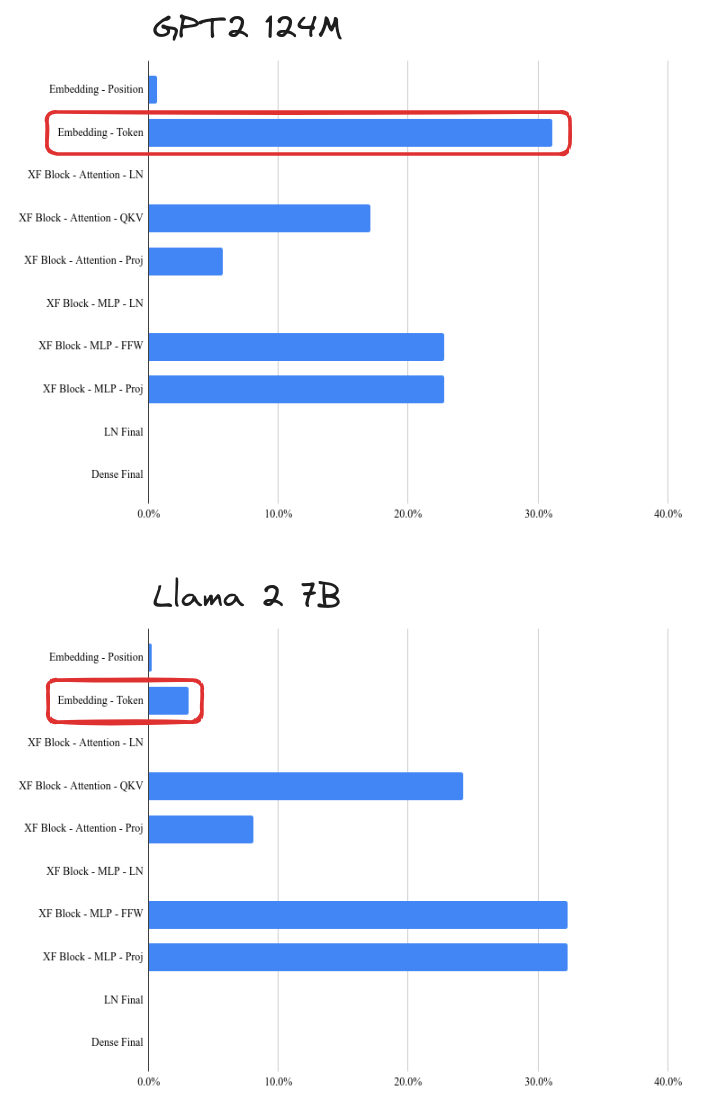
In particular, I’d been chasing something that is just not that important in many contexts. The relative parameter counts of the embedding vs the self-attention and feedforward layers of a transformer depend dramatically on the size and details of the network.
The top of the figure below shows the fraction of parameters for each param type of a GPT2-scale model (with 124M params, 12 layers,
The bottom shows the same for a 7B-scale LLM (with 6.7B params, 32 layers,
So chasing a way to shrink embedding sizes is just not super important when you are using these larger models!