These are notes on the epistemic foraging1 that has kept me busy during my sabbatical as I continue my pivot towards AI (as well as a few things I worked on earlier). (Info on my previous work history is here.)
Experiments
I’ve spent part of my time conducting some modest experiments. The ones I’ve had a chance to write up are cataloged here (with ideas for more as time permits).
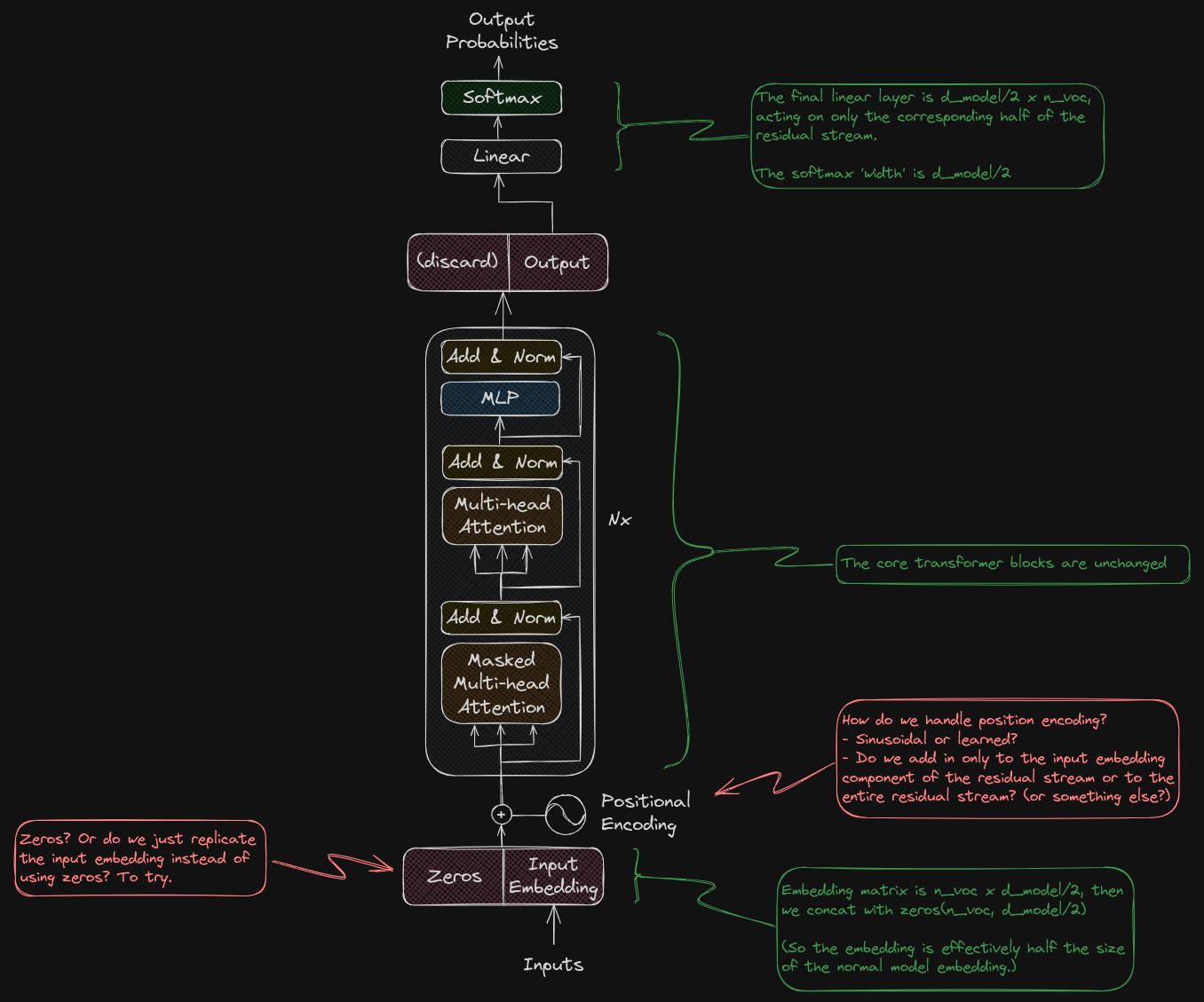
(figure from my residual stream data lane LLM experiment)
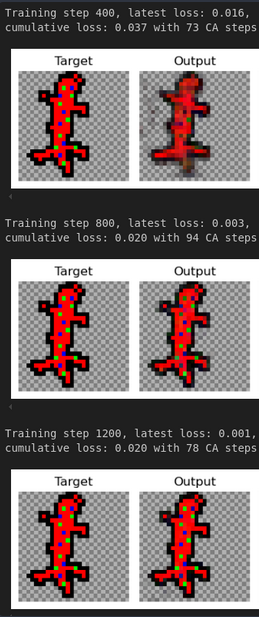
(figure from my neural cellular automata post)
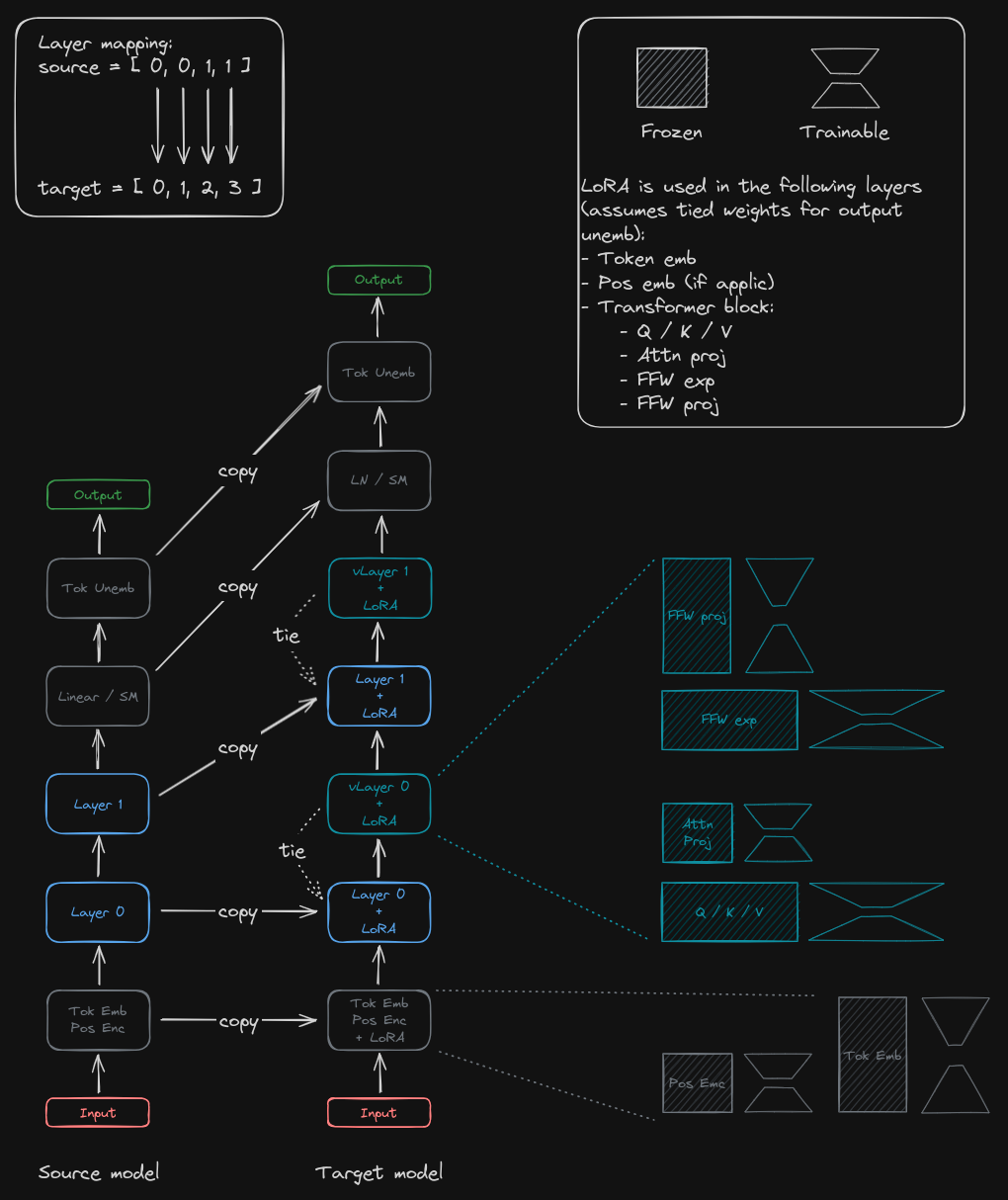
(figure from my virtual layer stacking transformer experiment)
Studies
Another big chunk of sabbatical time has been spent studying some of the AI-related topics I’m most interested in (see also my page about AI Research Interests):
- Mechanistic interpretability. I’ve read through a number of the amazing papers from Olah’s team at Anthropic, and I’m in the process of working through the very nice ARENA tutorials. It looks like David Bau’s group has also done some very good work, but I haven’t dug into that much yet. I love Neel Nanda’s work (although he’s difficult to keep up with!).
- Large Language Models (LLMs). Much of my recent experimentation has been with (large and not so large) language models. While I’m skeptical that LLMs—by themselves, as they exist today—are the path to advanced machine intelligence, I think they have a large role to play, and they are clearly giving us some great new tools to work with (for both research and business applications). I’m very interested in the trends towards democratization of these tools, from open weights and datasets to techniques that enable low-cost fine-tuning (like quantization, LoRA, and QLoRA).
- Diffusion models. The recent advances in diffusion models are fascinating, and I’ve been paying close attention to this generative AI (GenAI) sub-field. I’m interested not only in applications to images but to other domains as well (e.g., Diffusion-LM). Based purely on introspection I feel that our thought processes may be more akin to reverse diffusion than to autoregression, and I’m thinking about how that might manifest in approaches to language modeling, etc.
- Spiking Neural Networks (SNNs). I spent a couple of months doing a deep dive on this, and would love to spend more. There is a very interesting tradeoff between SNN approaches (that are fundamentally analogue) and the digital approach that is all the rage at the moment. SNNs offer the promise of dramatically lower power consumption, but—as Hinton has pointed out—the ability to trivially duplicate digital systems is really useful. Unfortunately, the lack of availability of SNN hardware for small-scale research is a real obstacle, and has prevented me from going too far with this.
- Neuroscience and human development. I spent a while doing a deep dive into neuroscience generally. I was all set to take the Neuromatch Academy summer school course at the start of my sabbatical, and really looking forward to it, but the timing didn’t quite work out with my Verizon departure. Instead I worked my way through Matthew Thiboust’s excellent Insights from the Brain and a number of the resources referenced there. I’m also a big fan of Josh Tenenbaum and his work.
- State Space Models. Transformers quickly became ubiquitous in NLP after their introduction in 2017, and since then have had a huge impact in other domains as well (images, some areas of RL, etc.). But I believe that over the next few years we’ll see our set of tools expand to other architectures. SSMs and their variants (Mamba, RetNet, RWKV) are a promising contender here, and I’m trying to get a grounding in these transformer alternatives.
- Neural Cellular Automata. I think these are really interesting and might have some overlap with AI and cognition. Read more about that here.
- MicroGrad and nanoGPT. Andrej Karpathy is a great teacher, and he has been kind enough to gift us with a bunch of helpful content. If you want to understand the basics of neural nets it is well worth your time to work through his Youtube videos and associated repos.
- Reinforcement Learning. Earlier in my studies (~2018) I spent a fair amount of time digging into RL, going through Sutton and Barto, learning about some of the recent algorithmic developments (e.g., PPO) and playing with OpenAI Gym.
Working with tools
Some tools that I’ve been spending time with:
- Python and PyTorch. While I have experience writing software in various languages—assembly language (!), Fortran (for my PhD dissertation analysis), bits of Java and Ruby, some R, a number of scripting languages—most of it is in either academic or personal / hobbyist settings. Coming up to speed on Python and Pytorch is my biggest weakness and one of the things I’m currently working on. I consider myself capable but slow; nowhere near as proficient as I want to be.
- Hugging Face. While you of course need to know how to do things like write your own training loop, these days you really have to assume proficiency with Hugging Face. Even if you aren’t using it in a prod setting, it is almost guaranteed that you’ll encounter it all over the place in the course of trying out new models, etc.
- llama.cpp, Open WebUI, Ollama, Text Generation UI, and SillyTavern. I’ve spent some time playing with pretrained LLMs (at least what I can fit on my machine in heavily quantized form). These tools are all nice for interacting with LLMs for daily chat and standing up APIs for use with other apps. When just playing around with LLMs I’m inclined to use a local 7—30B model (or hit the still-free Gemini-Pro!) rather than run up my bill with OpenAI or Anthropic or Mistral or whoever.
Personal projects and other stuff
CLIP for pic search
I’m the curator of our family photographs—at least the ones taken before phones with online storage arrived—and over the years I’ve collected something like 50k digital pics (including digitized versions of old analog family photos). (Digikam ftw as a management tool.)
Early in my AI exploration (pre-sabbatical) when CLIP was all the rage I hooked it up to my repository of images to enable search. It was a fun little project, allowing me to work on my Python scripting and the SBERT library.
Being able to search for “kids kayaking” or “camping by the river” and instantly pull up your pics from 15 years ago is pretty cool (although now we get that for ‘free’ with online services).
VQ-GAN Text to Image
My initial exposure to (early) text-to-image GenAI systems. Read about it here.

Anki!
Anki (for those not familiar with it) is like a superpower. Gone are the days when I start to read a research paper and think to myself “Haven’t I looked at this paper before??” Or struggled to remember (again) what the loss function for DPO looks like.
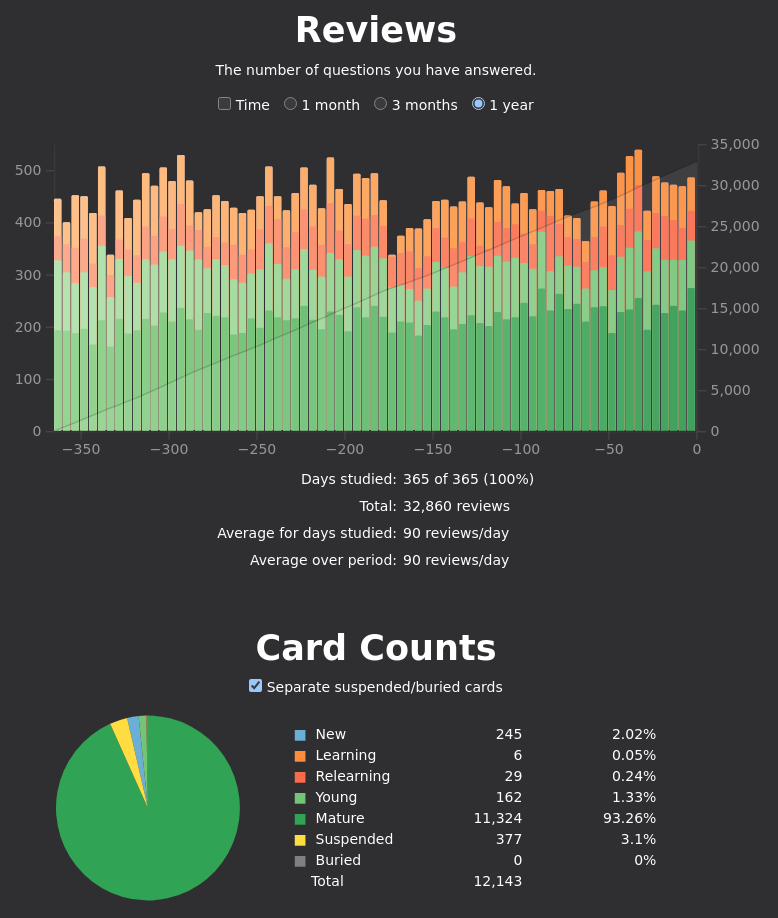
I spend about 1—1.5 hours per day reviewing cards and adding new ones; it is a big investment but one I think is well worthwhile. I got serious about Anki in 2019 and my only regret is that I didn’t start doing something like this 30 years sooner. Some stats from the last year of my main (primarily AI / ML-focused) deck:
People have a tendency to dismiss this type of thing as rote memorization. “Why would you bother memorizing things like that when you can just search for the answer?” That point of view completely misunderstands how humans learn and apply knowledge. Being able to remember things forms the lower layers of Bloom’s taxonomy, and is the foundation for attaining mastery of a topic. Things pop into place and ideas come together almost magically when they are readily available for your brain to work with.
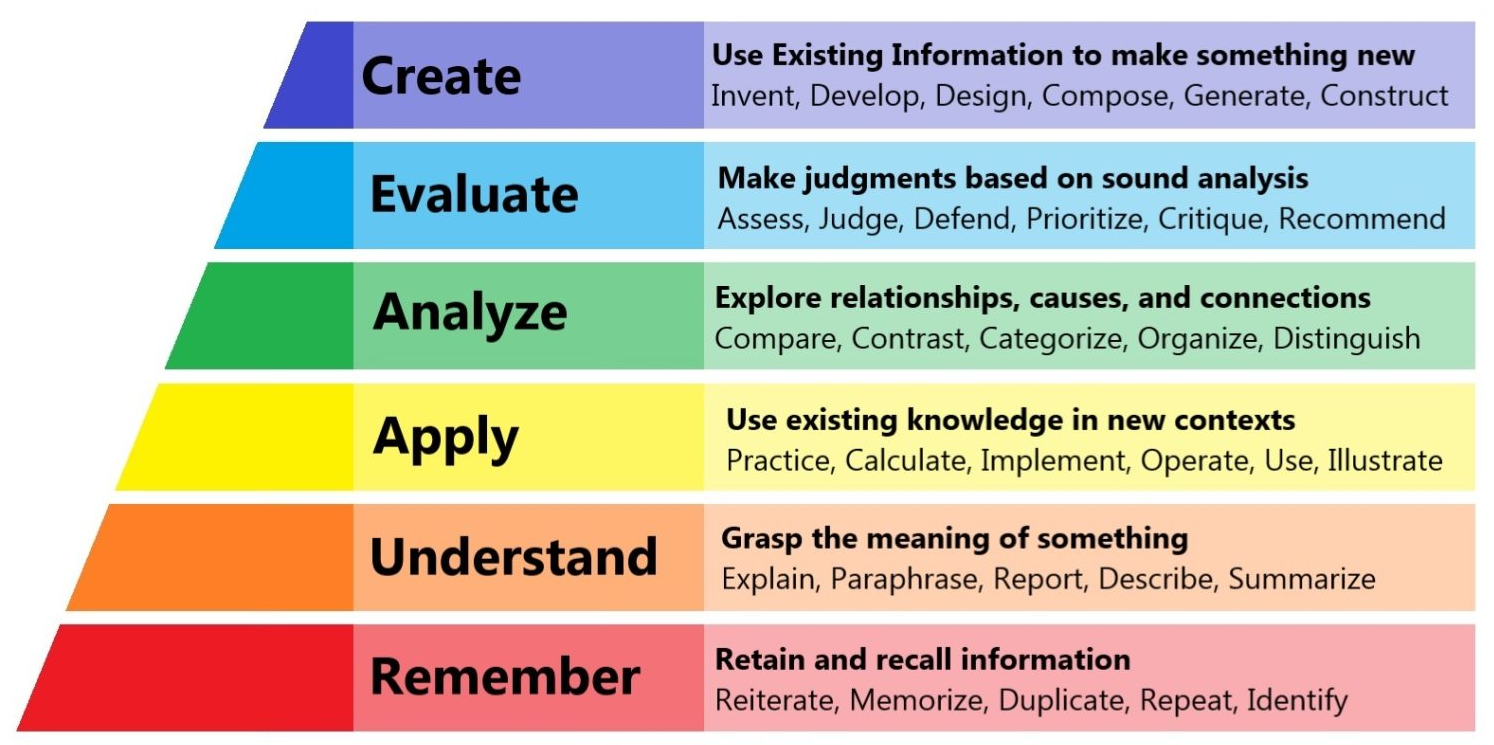
(image lifted from helpfulprofessor.com)
Obsidian
Over the last decade or so I’ve used a few different note-taking tools. For many years one called TiddlyWiki was my go-to, but I also tried Joplin and a few others. But all through those years there were various capabilities missing from whatever tool I was using, always prompting me to try something new.
That search for a better tool has pretty much ended now that I’ve found Obsidian. It is a beautifully-written piece of software that—together with a number of plugins created by the community of users—has addressed all of my note-taking wants. I use it on and off all day long, for documenting the little projects I’m working on, capturing ideas, taking notes about things I don’t want to forget, creating drawings, keeping daily notes, and on and on. People talk about it as a ‘second brain’, and that captures it pretty well. The team that created it are rock stars.
And you can connect Obsidian to Quartz and Github for publishing static sites, so I now use that combo for authoring this blog.
Zotero
For me, Zotero is like Anki and Obsidian, in that it is indispensable. Before I started using it I would either annotate standalone pdfs for papers I really cared about (ugh, what a mess), or I wouldn’t bother (and then would bang my head on the desk when I couldn’t remember what I was thinking the last time I looked at the paper!).
Having a single repository for all my notes on papers is so nice.
What I have not done is any sort of integration between Obsidian and Zotero. I know that some people have set up some clever workflows with those two tools, but I have not felt the need.
Deck reno
I spent sabbatical time working on my deck, so I get to talk about it here :)
Footnotes
-
This is a wonderful phrase that—as far as I can tell—can be attributed to Karl Friston (in the context of his Free Energy Principle). I take it to mean active exploration that an organism undertakes in an attempt to resolve uncertainty and disclose the structure of the world. ↩