The Idea
Note: This is a work in progress, with some partial results.
There have been indications recently that we can expand the capacity of LLMs by duplicating blocks (and then following up with some sort of fine-tuning). Two examples:
- Goliath-120B, in which layers from two separate fine-tunes of the same 70B model were interwoven to achieve a much larger model that (at least anecdotally) has very good performance.
- Solar 10.7B, in which the final 24 (of 32) layers of a pretrained 7B model were slapped onto the initial 24 layers of the same model (so taking the total number of layers from 32 to 48), then the whole thing fine-tuned (they call this depth upscaling) to achieve very good performance.
I’m very interested in improving models for low-resource scenarios, and the thought that occurred to me was: could we use virtual (that is, weight-tied) layers, each with LoRA-type adapters, to get significantly more layers (hence capability) out of a transformer with a lower parameter count (so less memory during inference) than simply increasing the number of layers?
Note that this wouldn’t do much to reduce VRAM required for training, since that is dominated by other considerations. Nor would it help with inference latency or throughput, since you are still walking through all the layers in the forward pass. But if it would help me fit a more capable model onto my little GPU, then that would be a step in the right direction! (Then separately you could look at introducing, say, mixture of experts to reduce latency.)
Here’s a diagram of what I did (although it shows a toy two-layer model just to convey the concept):
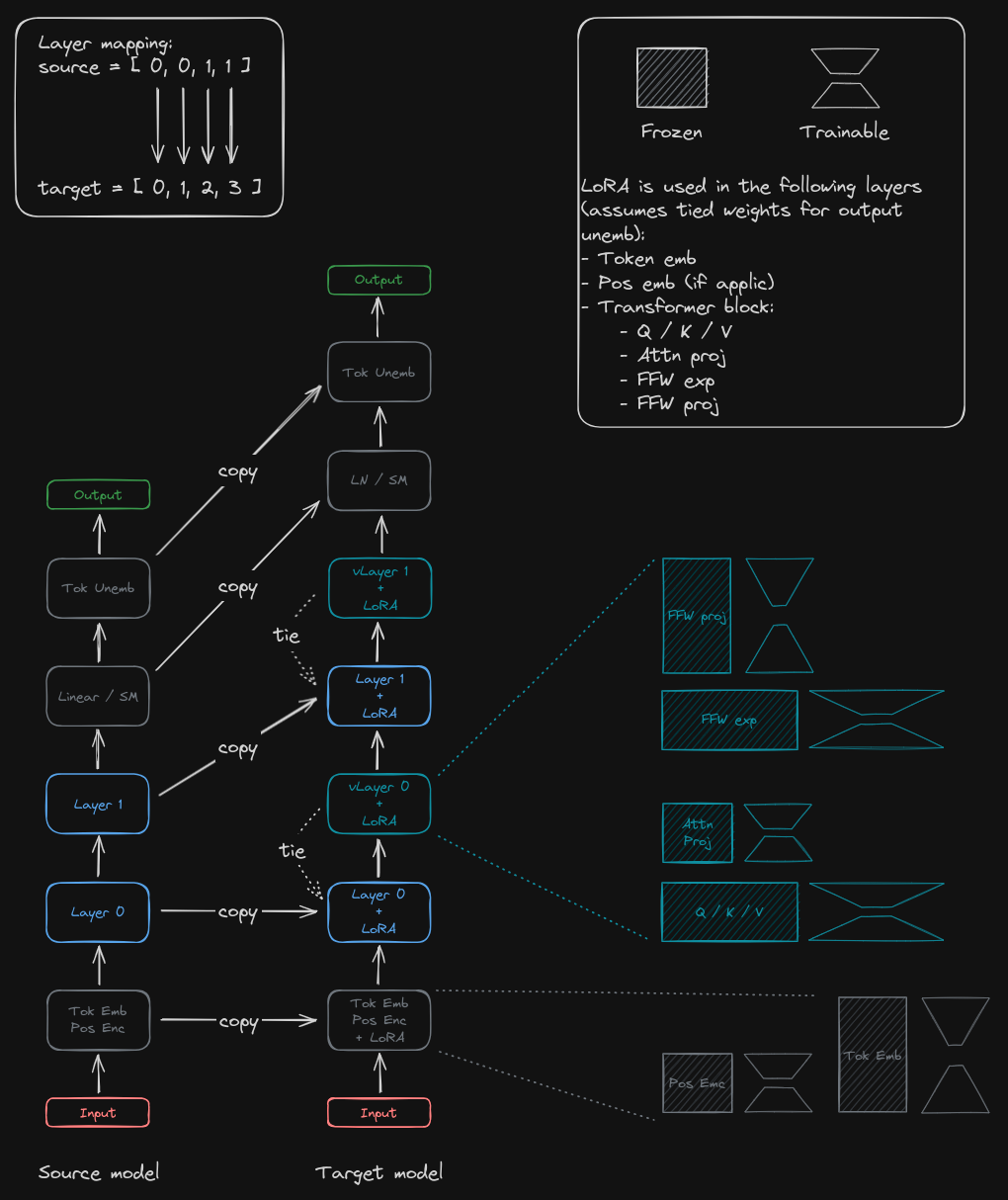
As indicated in the figure, I ended up adding LoRA (or IA3) adapters to both the ‘virtual’ (weight-tied) as well as the ‘real’ layers.
The Experiment
I did this work using the fully-trained (not by me) TinyStories-33M model. I grabbed a subset of this version of the TinyStories dataset to check perplexity out of the box. PPL = 4.41.
The first thing I was curious about, as a sort of pre-experiment: when you choose to copy real layers to virtual layers (see diagram above), what effect does the mapping from source model to target model have?
Below is a plot showing the results of a few experiments taking the 4-layer fully-trained TinyStories model and duplicating layers so that it is an 8-layer model. No fine tuning is done here.
Each row in the heatmap is a separate experiment, with resulting perplexity on the right. The row in the heatmap shows which of the four layers (0 - 3) of the original model was used for the eight layers (0 - 7) of the new model. For example, the top row shows that constructing the (8-layer) target model using layers [0, 1, 2, 3, 0, 1, 2, 3] from the (4-layer) source model resulted in a perplexity of 8.84.
So one interesting observation (perhaps not surprising) is that none of these mappings result in an 8-layer model that does better than the original 4-layer model. At this point, however, we have not applied any LoRA adapters, nor have we done any fine-tuning. We’re just gluing together layers as they were originally trained.
Another thing to note is that here I only tried mappings in which you keep the first and last layers in place. I did a little bit of testing where that rule was not respected, and it generally resulted in poorer perplexity.
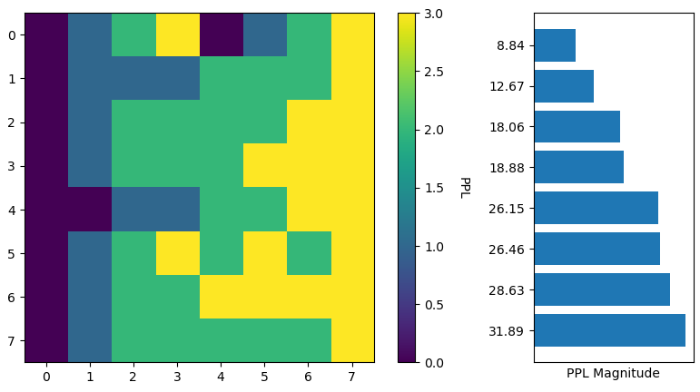
I decided at this point to focus on using the second row as the basis for further testing. In other words, the testing that follows used a mapping of [0, 1, 1, 1, 2, 2, 2, 3] for an 8-layer target model (and [0, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 3] for a 12-layer target).
The reason that I steered away from the best-performing option, the top row above, is that I was concerned that the model - by virtue of working through layers 0 to 3 two times - would be wasting compute just getting back to where it was before.
In all runs, I froze the main layer matrices and trained only the LoRA (or IA3) matrices (as depicted in the first figure above).
Results
I’m showing the training curves here (instead of end results) because in some cases when it became clear where the run was trending I got impatient and cut it short (these runs were taking 12 - 16 hours). All runs are also less than one epoch of a subset of the TinyStories dataset. (I’m re-training on data that the model saw in pretraining, which in retrospect is not the best idea.)
In this graph, all LoRA runs have rank=8, lora_alpha=16, and lora_dropout=0.1.
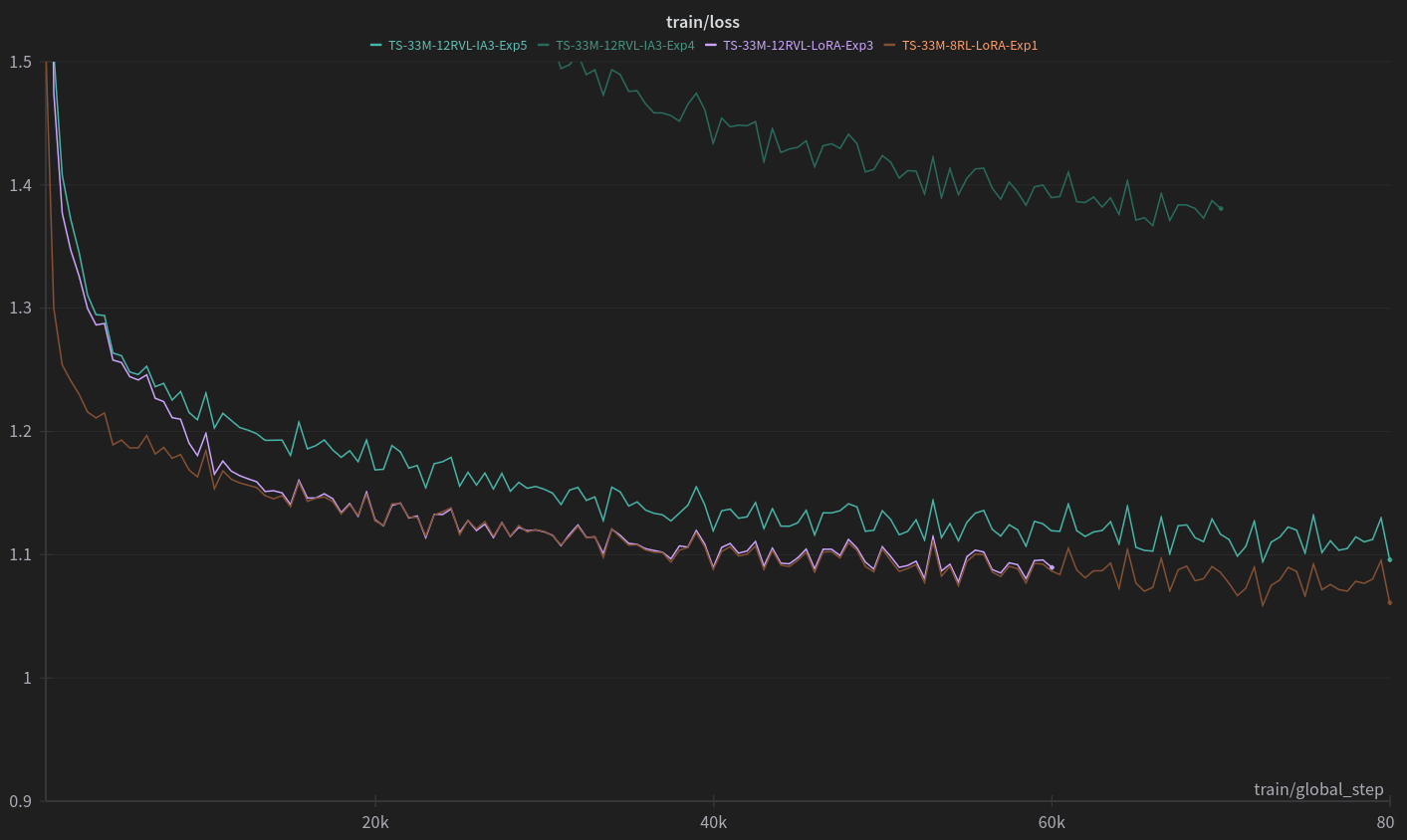
Notation for the different runs (TS-33M refers to the base TinyStories-33M model):
- TS-33M-8RL-LoRA-Exp1 (brown): Baseline. 8 ‘real’ layers, with LoRA, with source-to-target mapping of [0, 1, 1, 1, 2, 2, 2, 3]. In other words, I simply copied the four new layers from the original 4-layer model (as opposed to using weight tying), then trained some more (with base layers frozen, LoRA updates only). (The mix of 4 real + 4 virtual layers was very close to this baseline, as expected.) This baseline model got a PPL of 4.41, the same as the fully-trained 4-layer model.
- TS-33M-12RVL-LoRA-Exp3 (purple): 6 ‘real’ layers + 6 ‘virtual’ layers, all with LoRA. Basically converged to the same result as the baseline.
- TS-33M-12RVL-IA3-Exp4 (dark green): 6 ‘real’ layers + 6 ‘virtual’ layers, all with IA3 adapters. Here the IA3 adapters had a learning rate of 5e-5, which turned out to be way too low.
- TS-33M-12RVL-IA3-Exp5 (teal): Same as Exp4 above except starting with an LR of 3e-3. Significantly better but still doesn’t match the LoRA models.
To do
The results so far have been fairly disappointing; I was hoping that adding a bunch of (frozen) layers with fine-tuned adapters would give the model more capacity. That said, I think there is more worth pursuing here.
I need to do more work mapping out the difference between 4-, 8-, and 12-layer models. I also need to experiment with larger rank with LoRA and higher learning rate with IA3. As can be seen from the graph above, I’m also not waiting for the training to completely run its course; once it settles in and I have a good sense of where it’s going I’m off to another run.
2024-03 update: since starting this work I came across this MobileLLM paper in which they “propose an immediate block-wise weight sharing approach with no increase in model size and only marginal latency overhead,” which sounds very similar to what I’m doing (I have not dug into details). They see less than 1% gain in accuracy from this technique, which is not very encouraging.
Repo: (#to do#)