Sometime around the summer of 2021 I came across the paper Pretrained Transformers as Universal Computation Engines (Lu et al., 2021), and was blown away. In this paper the team from UC Berkeley, FAIR, and Google took a GPT-2 (pretrained as a language model in the usual way), then froze the self attention and feed forward parameters (keeping the embedding / output layer and layer norm params trainable). The learned parameters accounted for well under 1% of the total model params.
They proceeded to train this model on several very diverse tasks like bit operations, image classification, and protein folding predictions. Amazingly, the mostly-frozen GPT performed about as well as one trained from scratch on these tasks.
Wow! The idea that one could take a model pretrained on natural language and then, by retraining such a small fraction of the parameters, have it perform well on seemingly unrelated tasks seemed absolutely crazy to me.
Then a while later I encountered another paper (which had come out about the same time): FNet (Lee-Thorp et al., 2022). Here a team from Google takes an encoder-style model (think BERT) and replaces the self-attention layers with parameter-free Fourier transformations that mix information across tokens in the input sequence. In other words, there was no trained self-attention mechanism, just a sort of channel mixing that the model needed to learn how to make use of (via parameters in the surrounding feed-forward layers). They pre-trained using masked language modeling and then fine-tuned on various NLP tasks.
FNet didn’t outperform vanilla transformers, but it came close, and used less compute.
I think of both of these concepts as providing a ‘frozen attention’ substrate surrounded by trainable components that can learn to make use of the frozen mixing between channels.1 It’s like the trainable system is given a set of tools that do something, and they have to figure out how to best make use of the tools.
I refer to these approaches, in a likely abuse of terminology, as forms of reservoir computing.2 I’m excited about them partly because I find it fascinating that they work at all, but mostly because they may offer a route to do more with less. Do they allow models to punch above their weight class in terms of 1) lower compute or lower memory for a given level of performance, or 2) faster training? And could they be leveraged for either different use cases or different modalities at the same time? I think the idea is under-explored.
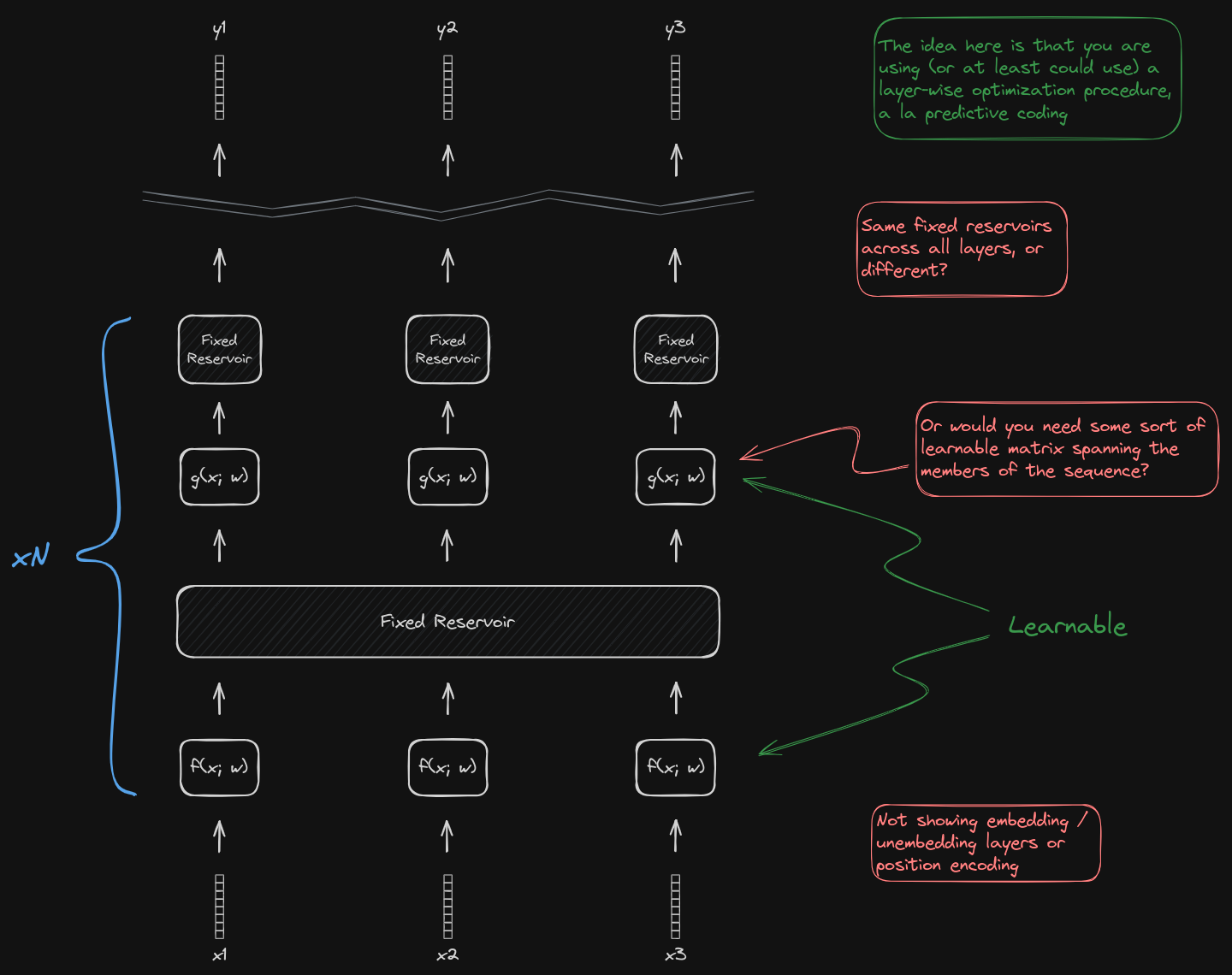
Footnotes
-
Another paper in a similar vein is MLP-Mixer (Tolstikhin et al., 2021). Here the proposal was to replace the self-attention layers with MLPs that—instead of operating within each token’s stream—were ‘rotated’ and operated across tokens. In this case, however, the MLP layers remained trainable. ↩
-
Technically reservoir computing refers to the use of a fixed recurrent network to process sequential data, with only the output layer trained. Is there a better term? ↩