This post about Hinton’s capsule network concept makes the following claim:
Imagine a face. What are the components? We have the face oval, two eyes, a nose and a mouth. For a CNN, a mere presence of these objects can be a very strong indicator to consider that there is a face in the image. Orientational and relative spatial relationships between these components are not very important to a CNN.
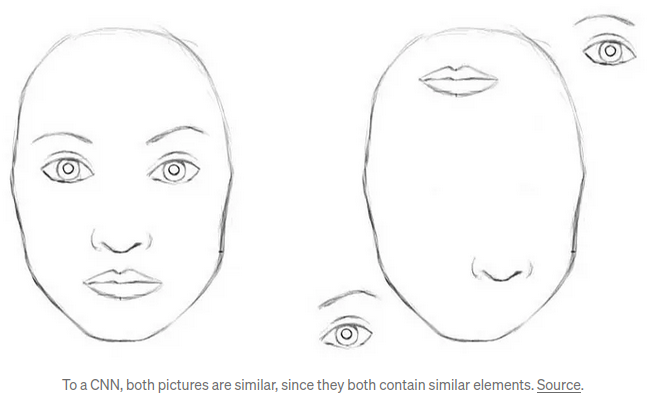
Is this true, and to what extent? If so, is it true also for ViTs? I don’t think I’ve ever seen this idea discussed or quantified. It would be a cool little experiment.